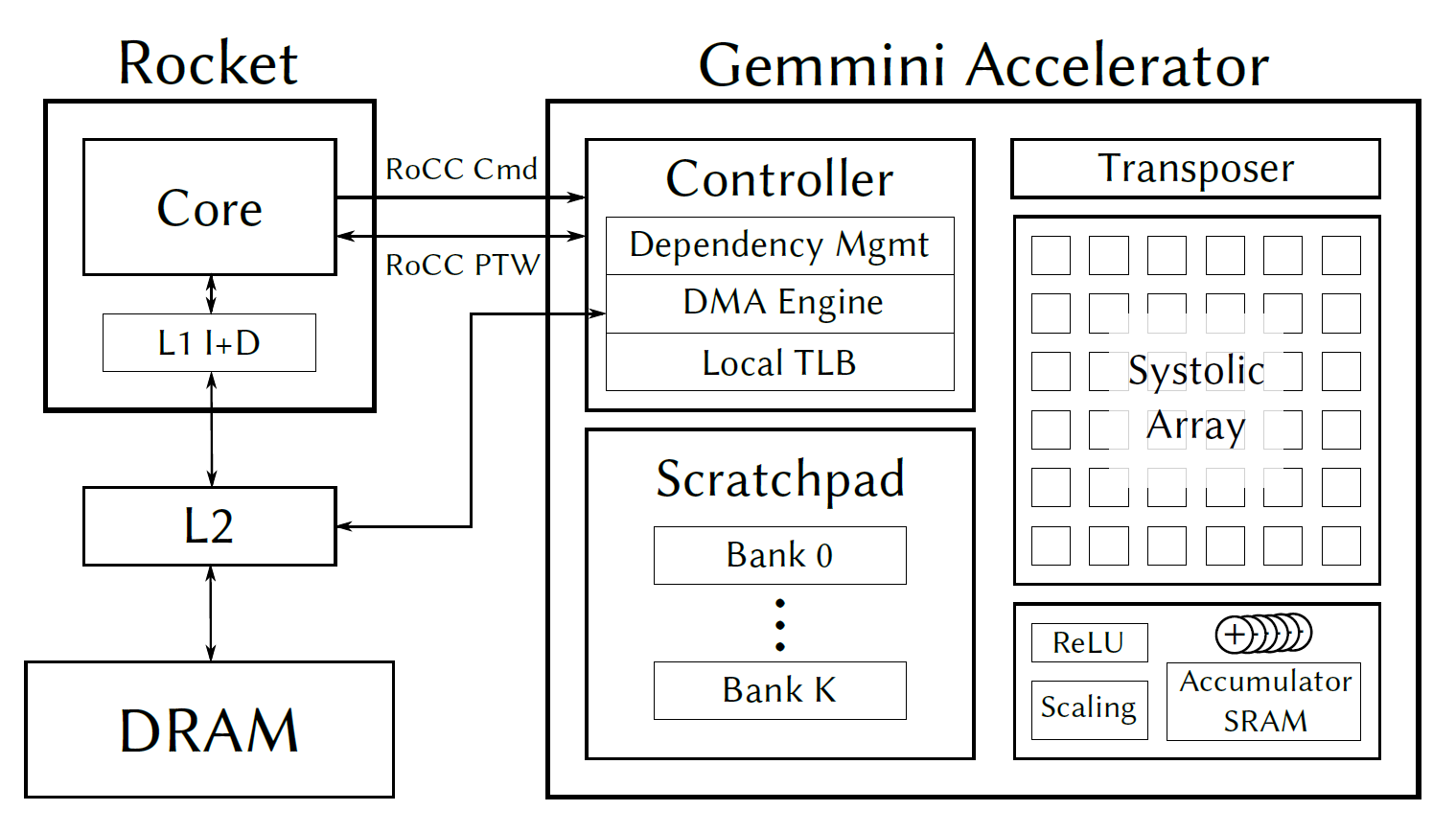
Research problem
Gemmini accelerates transformer matmul on a 16×16 systolic array. After QKT, int32 scores sit in the accumulator; PV needs int8 weights in the scratchpad. The official path materializes the full attention matrix in DRAM between those two on-chip memories — pure data-movement overhead for a value consumed immediately.
A natural first fix is to fuse the store locally (skip DRAM). That works at short sequences but collapses at longer ones because Gemmini's built-in softmax still requires a full-row scan across every J-tile. The bottleneck is not missing softmax hardware — it is the wrong softmax algorithm mapped onto tiled accumulator memory.
Attention fusion — keeping weights on-chip
The baseline Gemmini attention path computes QKT into the accumulator, softmaxes via the Normalizer, mvouts the N×N attention matrix to DRAM, then mvins it back for PV — even though PV only needs those weights in the scratchpad. That is pure data-movement waste.
Part 1 — Data-movement fusion (Exp 1)
Route softmax output to scratchpad using GEMMINI_LOCAL_STORE_FLAG instead of a DRAM
address. PV uses A=NULL — weights are already in SP. Zero attention-matrix DRAM traffic.
Part 2 — Online softmax hardware (Exp 5)
Fusion alone still uses full-row built-in softmax → blows up at seq≥256. OnlineAttention completes the fusion story with block-wise online softmax in dedicated RTL.
Three pipelines compared
seq=128: ~393 KiB/layer wasted DRAM traffic (12 heads × N² int8 write+read).
Wins at seq=128 (attn 611K→358K). Fails at seq=256 (~6.4× slower attn) and crashes at 512. Fusion idea validated; softmax engine was wrong.
Same zero-DRAM fusion path, but softmax streams K-blocks incrementally. Scales cleanly to seq=512.
| Baseline | Exp 1 fused | Exp 5 | |
|---|---|---|---|
| Softmax output goes to | DRAM (mvout) | Scratchpad (local store) | Scratchpad (OnlineAttention) |
| PV A operand | DRAM → mvin → SP | SP (A=NULL) | SP (A=NULL) |
| Attn matrix in DRAM | 12×N² int8 per layer | Never leaves chip | Never leaves chip |
| Softmax algorithm | Full-row Normalizer | Full-row Normalizer | Block-wise online |
Performance
Verilator simulation, IBertGemminiRocketConfig, BERT-base attention sublayer
(QKV proj + 12-head attention + Wo + LayerNorm). Same simulator for all configs.
Full sublayer breakdown
| Component | Baseline | Exp 1 | Exp 5 |
|---|---|---|---|
| QKV projection | 960K | 962K | 913K |
| Attention core | 611K | 358K | 245K |
| Wo projection | 309K | 309K | 309K |
| LayerNorm | 188K | 176K | 164K |
| Total | 2.15M | 1.88M | 1.63M |
Attention core: 611K → 358K (fusion only, −41%) → 245K (fusion + online softmax, −60% vs baseline).
| Component | Baseline | Exp 1 | Exp 5 |
|---|---|---|---|
| QKV projection | 1.85M | ~1.85M | 1.80M |
| Attention core | 1.04M | ~6.68M | 486K |
| Wo projection | 610K | ~610K | 609K |
| LayerNorm | 395K | ~395K | 369K |
| Total | 3.97M | ~9.5M | 3.27M |
Exp 1 at seq=256: fusion removes DRAM but full-row softmax makes attention 6.4× slower than baseline. OnlineAttention fixes this.
| Component | Baseline | Exp 1 | Exp 5 |
|---|---|---|---|
| QKV projection | 3.63M | CRASH | 3.58M |
| Attention core | 2.62M | — | 1.88M |
| Wo projection | 1.20M | — | 1.20M |
| LayerNorm | 801K | — | 759K |
| Total | 8.34M | CRASH | 7.43M |
Exp 1 crashes at seq=512 (TileLink assertion). Exp 5 is stable with zero attention-matrix DRAM traffic.
Attention core only (where fusion + online softmax matter)
Key takeaways
-
Attention fusion removes pointless DRAM traffic. Routing softmax output to scratchpad
(
GEMMINI_LOCAL_STORE_FLAG,A=NULLfor PV) eliminates the N×N matrix round-trip. - Fusion alone does not scale. Exp 1 proves the data-movement analysis was right (611K→358K attn @ seq=128) but full-row softmax causes ~6.4× slowdown at seq=256.
- Online softmax hardware completes the design. OnlineAttention makes fusion work at seq=512 with attn core 245K vs 611K baseline @ seq=128.
OnlineAttention hardware (completes the fusion)
OnlineAttention.scala — a new Gemmini module dispatched via RoCC funct=23.
It reads accumulator scores directly (raw ACC bypass), maintains per-row online softmax state
(max, sum, rescale; up to 256 rows), runs 16 parallel iexp units per DIM chunk,
and writes int8 weights to scratchpad.
| Component | Role |
|---|---|
OP_FUSED_BATCH |
Single RoCC cmd: BATCH_UPDATE → BATCH_WEIGHTS per Q-block |
Controller.scala |
Dispatch, ACC/SP port arbiters, busy OR-tree |
Scratchpad.scala |
Raw accumulator read bypass (post-fence) |
gemmini.h |
gemmini_oa_* software API for benchmarks |
End-to-end pipeline (Exp 5): QKT → online softmax in hardware → PV with A=NULL. Three RoCC commands per head; zero attention-matrix DRAM traffic.
Why default Gemmini softmax fails at scale (DIM=16)
One attention row spans SEQ_LEN columns in accumulator SRAM, tiled as
J-tiles of 16 (DIM). The built-in Normalizer on mvout scans
every J-tile in three passes — MAX, SUM_EXP, normalize — before any weight is valid.
Example: SEQ=64 → 4 J-tiles. SEQ=128 → 8; SEQ=512 → 32. Each tile = one DIM-wide ACC read, 16 parallel lanes.
OnlineAttention: streaming K-blocks
Instead of three full-row passes, the module keeps running state per row and processes one K-block (16 columns) at a time — the same tiling Gemmini already uses, but with FlashAttention-style online updates.
Per K-block: BATCH_UPDATE merges max/sum, then BATCH_WEIGHTS writes 16 int8 weights to scratchpad.
Scratchpad weights (int8)
Design journey
An iterative experiment path — useful to discuss in research interviews:
Official Gemmini attention: QKT → full-row SOFTMAX → DRAM → mvin → PV. DRAM traffic dominates.
Scratchpad-local-store removes DRAM. Wins at seq=128 (611K→358K attn cycles) but full-row Normalizer causes ~6.4× slowdown at seq=256 and simulator crash at 512.
ISA conflicts and stat_id hacks. Conclusion: online softmax needs its own module, not a bolt-on to mvout.
~700 lines Chisel, integrated into Controller/Scratchpad. Exp 5: fair end-to-end sublayer numbers, Qblock sweep, definitive comparison on one simulator.
Further analysis
The sections above are the headline story. Below is the supporting analysis from the full report — useful if you want the “why” behind the numbers without reading 16 pages of PDF.
Prior art and framing
FlashAttention streams K/V blocks and keeps online softmax statistics
(m, ℓ) so the full N×N matrix never sits in GPU HBM. Our setting is different:
a RoCC-attached systolic accelerator with separate scratchpad and
accumulator, a built-in Normalizer on the mvout path, and
i-BERT fixed-point iexp. The idea is the same — fuse softmax with where scores
already live — but the mechanism is Gemmini-specific RTL, not a CUDA kernel.
Why optimize attention if QKV is ~45% of cycles?
At seq=128 the baseline spends ~960K cycles on QKV projection vs ~611K on the attention core. QKV must load weights and activations from DRAM at least once. The attention matrix P is different: it is produced on-chip, immediately consumed by PV, yet the official path still writes and reads it through DRAM (~393 KiB/layer at seq=128; ~6.3 MiB at seq=512). That traffic is avoidable — the main removable cost.
| Baseline @ seq=128 | Cycles | Share |
|---|---|---|
| QKV projection | 960K | 44.7% |
| QKT + softmax | 345K | 16.0% |
| PV | 266K | 12.4% |
| Attention core (total) | 611K | 28.4% |
| Wo + LayerNorm | 497K | 23.1% |
Why Exp 1 collapses: the O(N²) control storm
Fusion removes DRAM, but Exp 1 still drives built-in full-row softmax through thousands of small mvout-style operations. With Qblock=16, each Q-block pays roughly 48 × (N/16) store passes across the full J dimension; multiplied by N/16 Q-blocks per head, total mvout-class work scales as O(N²).
| Seq | mvout / head (approx) | Attn core | Outcome |
|---|---|---|---|
| 128 | ~3,072 | 358K (Exp 1) | DRAM savings win |
| 256 | ~12,288 | ~6.68M (Exp 1) | ~78% RoCC overhead vs matmul |
| 512 | ~49,152 | CRASH | TileLink stress |
OnlineAttention replaces per-slice mvout with batched ACC reads and one
OP_FUSED_BATCH per Q-block — that is the mechanism change Exp 1 could not get
by redirecting softmax output alone.
Qblock sweep — granularity dominates after fusion
Once attention-matrix DRAM traffic is zero, performance is often set by how many times the scalar core launches matmul and custom-op sequences. Exp 5 swept Qblock ∈ {16, 64, 128, 256} on the attention core (Kblock=N):
| Seq | Q=16 | Q=64 | Q=128 | Q=256 | Optimal |
|---|---|---|---|---|---|
| 128 | 374K | 251K | 238K | — | 128 |
| 256 | 955K | 531K | 486K | 471K | 256 |
| 512 | 3,504K | 1,982K | 1,825K | 1,883K | 128 |
At seq=128 and 256, larger Qblock wins: RoCC dispatch savings outweigh accumulator spill. At seq=512, Q=256 becomes worse than Q=128 (+3.2%) — a U-curve where ACC overflow DMA exceeds the benefit of fewer Q-blocks. ACC_ROWS=2048 caps how large Qblock can go; doubling accumulator depth would likely shift the optimum rightward.
Bottleneck shift across the project
| Phase | Dominant limit | Evidence |
|---|---|---|
| Baseline | DRAM attn traffic + matmul | ~393 KiB/layer round-trip for P |
| Exp 1 @ seq=128 | DRAM removed; matmul wins | ~1.51× attention core |
| Exp 1 @ seq=256 | RoCC / mvout schedule | ~78% overhead vs real matmul |
| Exp 4 early | CPU score extraction + per-row cmds | Slower than Exp 1 despite fusion |
| Exp 5 | Matmul + ACC spill trade-off | Near-linear scaling; U-curve @ 512 |
What Exp 5 fixed over Exp 4
OP_FUSED_BATCH— one RoCC command for UPDATE→WEIGHTS per Q-block (vs two)- Zero
printfinside timed regions (~10²K cycles noise at seq=128) - Qblock chosen from sweep evidence, not fixed at 16
- Baseline, Exp 1, and Exp 5 all on the same Verilator binary
Correctness
Cycle counts come from timed Verilator regions only. Numerical checks use hardware-matched reference softmax outside the timed bracket — outputs were validated during bring-up (Exp 4 micro-tests through full BERT-scale integration); the reported speedups are for the measured pipeline, not unchecked RTL.
Limitations (scope of claims)
- Simulation only — Verilator cycle counts; no FPGA frequency, area, or energy.
- Single attention sublayer — not a full 12-layer BERT forward pass or training.
- Fixed geometry — DIM=16, WS dataflow, ACC_ROWS=2048.
- P fused, V not — attention weights stay on-chip; V still reloads from DRAM each Q-block in Exp 5.
- CPU orchestration — the scalar core still loops over heads/Q-blocks and issues separate RoCC/matmul commands with fences between stages.
- Exp 1 local-store —
GEMMINI_LOCAL_STORE_FLAGis a software convention in our benchmarks; examined RTL does not decode that bit to bypass TileLink — the win is schedule-level, not a new mvout hardware path.
Full detail: Final Report (PDF) · experiment timeline · architecture notes
Artifacts & reproduction
Repository layout
hardware/.../OnlineAttention.scala— Chisel modulebenchmarks/exp{1,4,5}/— C workloads + cycle counterspatches/— unified diff vs upstream Gemmini
export CHIPYARD=/path/to/chipyard
cd scripts
VERILATOR_THREADS=16 ./exp5/run_exp5_full_seq128.shIvan Lok, Data-Movement-Aware Optimization of Transformer Attention on Gemmini, ELEC 5140 Advanced Computer Architecture, HKUST, May 2026.